
Mastering Apache Spark Executor Tuning: A Practical Guide
Optimizing Spark Executors for Maximum Performance

Optimizing Apache Spark performance is crucial for large-scale data processing. One of the key aspects of optimization is tuning executors, which includes configuring the number of executors, executor cores, and executor memory. This guide breaks down the process step-by-step, ensuring your Spark applications run efficiently.
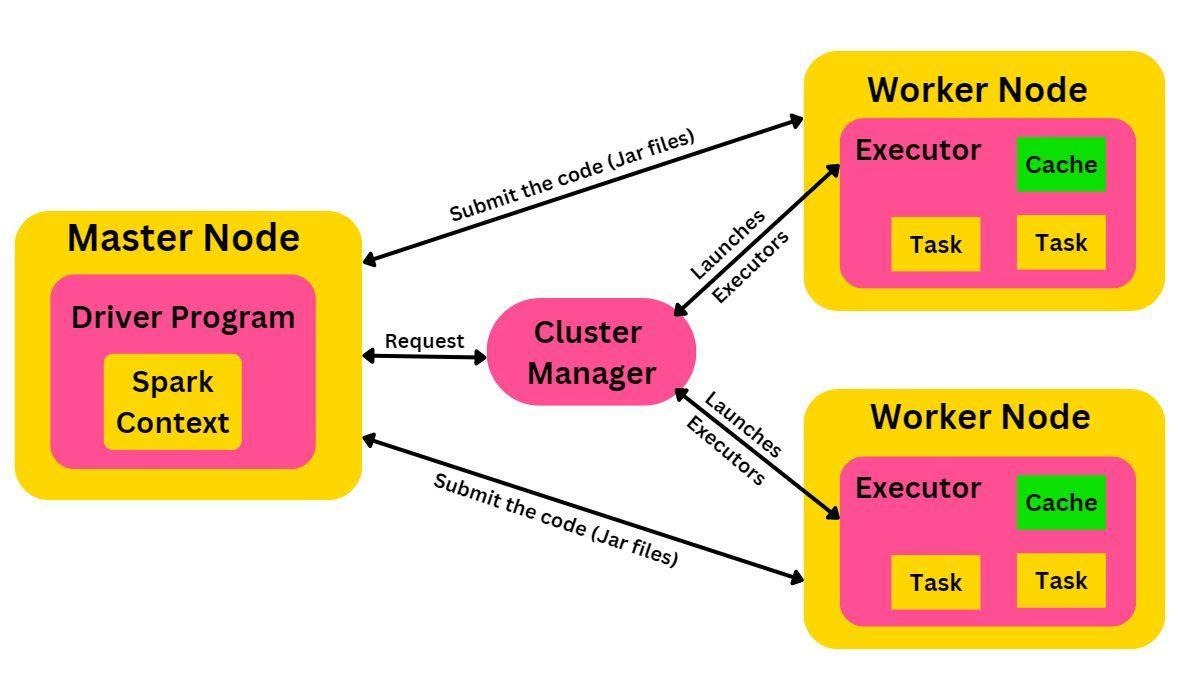
Understanding Spark Executors and Resource Allocation
An executor is a JVM instance that runs Spark tasks. Optimizing the number of executors, cores, and memory is essential for efficient resource utilization.
Case Study: Cluster with 6 Nodes (Each with 16 Cores and 64 GB RAM)
Reserve System Resources: Each node requires approximately 1 core and 1GB RAM for OS and Hadoop daemons, leaving 15 cores and 63GB RAM available per node.
Choose the Number of Cores per Executor:
The ideal number of cores per executor is 5 (for optimal parallelism and task execution).
This is a recommended best practice based on research, regardless of the total cores available.
Calculate the Number of Executors:
Available cores per node: 15
Executors per node: 15 / 5 = 3
With 6 nodes, the total number of executors: 6 × 3 = 18
Subtract 1 executor for ApplicationMaster (YARN): 17 executors
Calculate Memory per Executor:
Available memory per node: 63GB
Memory per executor: 63GB / 3 = 21GB
Deduct overhead memory: Max(384MB, 0.07 × 21GB) = 1.47GB
Final executor memory: 21GB - 1.47GB ≈ 19GB
Final Configuration:
--num-executors 17--executor-cores 5--executor-memory 19GCase Study: Cluster with 6 Nodes (Each with 32 Cores and 64 GB RAM)
Maintain 5 cores per executor for efficiency.
Executors per node: 32 / 5 ≈ 6
Total executors: 6 × 6 - 1 = 35
Memory per executor: 63GB / 6 ≈ 10GB
Overhead: 0.07 × 10GB ≈ 700MB (round to 1GB)
Final executor memory: 10GB - 1GB = 9GB
Final Configuration:
--num-executors 35--executor-cores 5--executor-memory 9GAdjusting Cores and Executors Based on Memory Needs
If a Spark application requires less memory per executor, we can adjust the number of executors accordingly. Example:
If 10GB per executor is sufficient instead of 19GB, we can allocate 6 executors per node instead of 3.
This increases the number of executors while reducing the cores per executor (from 5 to 3) to fit within available resources.
New calculations:
Executors per node: 15 cores / 3 cores per executor = 5 executors
Total executors: 5 × 6 - 1 = 29
Memory per executor: 63GB / 5 ≈ 12GB
Overhead: 0.07 × 12GB ≈ 840MB (round to 1GB)
Final executor memory: 12GB - 1GB = 11GB
Final Configuration:
--num-executors 29--executor-cores 3--executor-memory 11G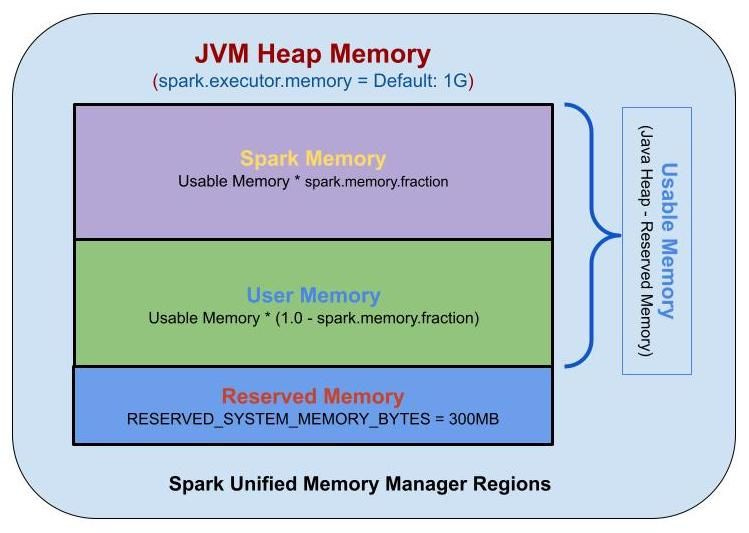
Dynamic Resource Allocation in Spark
Spark supports dynamic allocation of executors, which allows resources to be allocated dynamically based on workload.
Key Configuration Parameters:
Enable Dynamic Allocation:
spark.dynamicAllocation.enabled = trueSet Executor Limits:
spark.dynamicAllocation.minExecutors = Xspark.dynamicAllocation.maxExecutors = YSpecify Initial Executors
spark.dynamicAllocation.initialExecutors = ZTrigger Additional Executors:
spark.dynamicAllocation.schedulerBacklogTimeout = 1sIf tasks are waiting in the queue for 1 second, a new executor is requested.
The number of requested executors grows exponentially (1, 2, 4, 8, etc.) until maxExecutors is reached.
Release Idle Executors:
spark.dynamicAllocation.executorIdleTimeout = 60sExecutors that remain idle for 60 seconds will be removed to free up cluster resources.
Additional Considerations
Standalone Mode:
By default, Spark allocates one executor per worker node.
To increase the number of executors per node, set:
spark.executor.cores = XMemory Fraction:
Controls the proportion of JVM heap used for execution vs. storage.
If caching is not required, set spark.memory.fraction = 0.1 to allocate maximum memory to computation.
Check memory usage with:
sc.getExecutorMemoryStatus.map(a => (a._2._1 - a._2._2)/(1024.0*1024*1024)).sumConclusion
Optimizing Spark executors is not a one-size-fits-all process; it depends on the cluster setup, workload, and memory requirements. However, a structured approach to tuning ensures efficient resource utilization and better performance.
Key Takeaways:
Start with 5 cores per executor for optimal parallelism.
Divide available memory per node by the number of executors.
Subtract overhead memory before finalizing executor memory.
Use dynamic allocation for flexible resource management.
Monitor and adjust based on workload performance.
By following these best practices, you can ensure that your Spark applications are well-optimized, resource-efficient, and performant.